2022-03-16 | 1355 ![]() Print
Print ![]() PDF
PDF
Avoid Duplicate Content SEO that is the number one rule in content marketing and in ranking your SEO content, hence in order not to get the most used terminology confused, I will like to explain the basic compositions of duplicate content, as we have different variations of what can be termed as duplicate content in SEO and for the most latter part, a research conducted by raven shows that almost 30% of websites online do suffer from duplicate content affecting their SEO ranking.
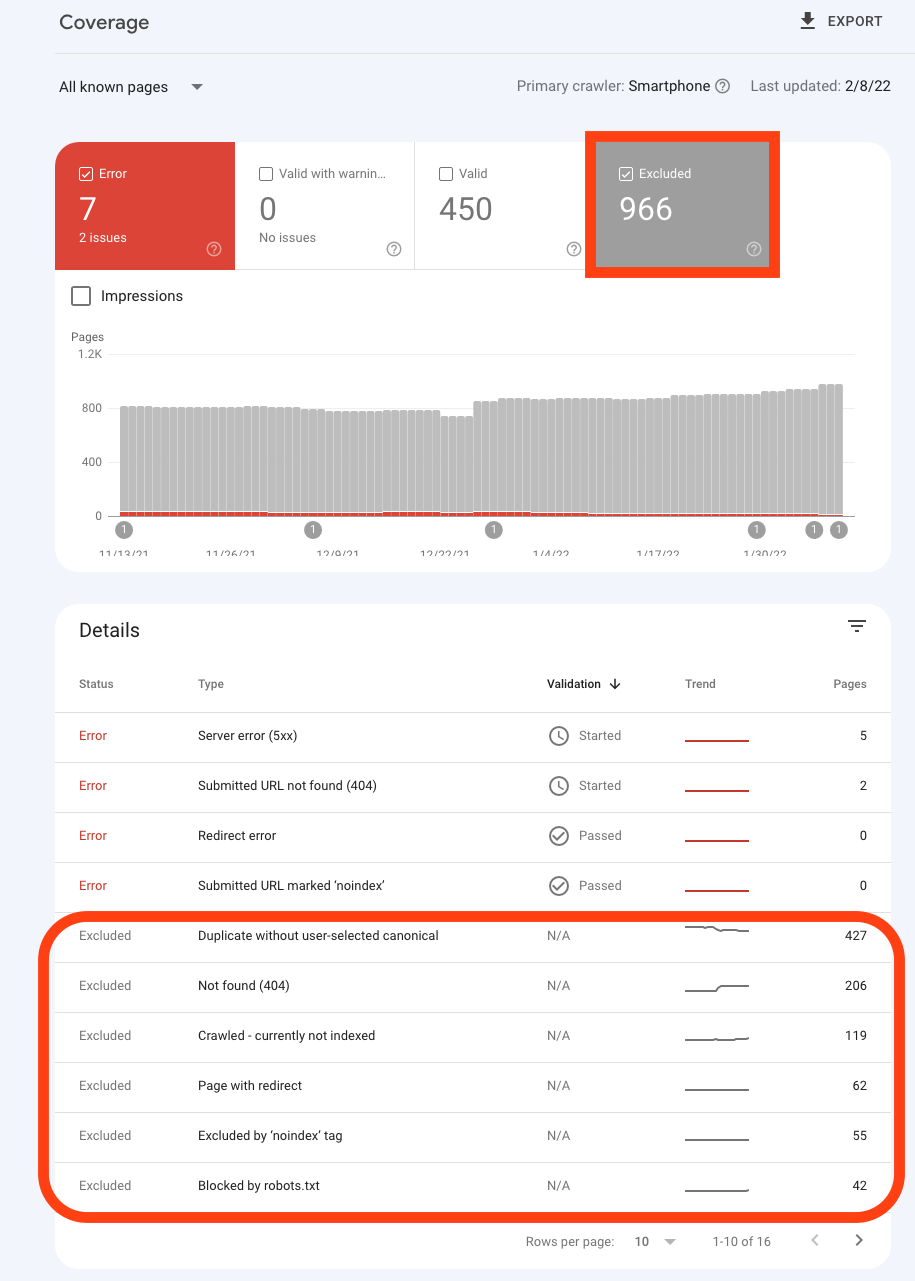
This reveals that duplicate content is like a virus that keeps affecting even the most valid websites you can ever think of, mostly common with dynamic websites with thousands of pages and their different levels of duplicate content SEO impact negatively either with a loss in ranking or a page not being indexed (You will find such pages mostly in your excluded pages on your search console dashboard).
Duplicate content refers to very similar or the exact match of content existing in multiple places within the same domain name and in SEO this can range from having the same META-TAGS across all web pages to having the same content or duplicate content URLs ranking on search engines having duplicate content ranking for same keywords, for a more elaborate definition let's quote from Wikipedia.
Duplicate content is a term used in the field of search engine optimization to describe content that appears on more than one web page. The duplicate content can be substantial parts of the content within or across domains and can be either exactly duplicate or closely similar... as defined by Wikipedia
Even Google's first-hand policy makes it clear to avoid creating duplicate content whether deliberately or erroneously, which is the case most times, and their definition of what duplicate content is can be read in the image below likewise.

This is why it is also advisable to run duplicate content SEO checker or duplicate content SEO tool to easily analyze your web pages for issues, apart from relying on the Google search webmaster tool, as this tool only focuses on the URLs, like the image screenshot above, the duplicate error message is one of it's kind, as there are others that follow in suit you can read more on this issues and others via How To Fix Google Index Coverage Issues.
How To Fix Duplicate Content.
This coverage issue seems to be the most popular index warning, moreover, I think Google now has a thing for the canonical tag, meaning in most cases you are required to add this tag into your HTML if not the current page will be assumed as the original page (that is what canonical means, don't index the current page you are on, but the one in the canonical URL).
Our Solution: you can fix duplicate content by viewing all affected pages and then specify the original canonical URLs we want Google to index or place the suggested one by Google on each page.
This is quite a bizarre issue, it simply means you submitted a URL for indexing, which turns out to be a duplicate of another URL without you specifying a canonical URL on either, this, in turn, prompts google to choose a preferred canonical version to be an indexed version for you. The difference between this status and "Google chose different canonical than user" is that here you have explicitly requested indexing.
Our Solution: You can fix duplicate content by simply add the rel=canonical tag to these pages pointing to their exact URL.
This happens when a page is marked as canonical for a set of pages, but Google thinks another URL makes a better canonical. Google has indexed the page that is considered canonical rather than the one you have selected.
Our Solution: We recommend to fix duplicate content of this nature, that you explicitly mark this page as a duplicate of the canonical URL. This page was discovered without an explicit crawl request. Inspecting this URL should show the Google-selected canonical URL.
These are the few duplicate content issues I can fish out from Google webmaster tools, and like you would have noticed they are related to URLs, now there is still other duplicate content that impact SEO, and I will like to talk about those ones.
The most obvious is to have the same Meta-tags description repetition, this might be due to auto page creation, mostly CMS websites are victims and they are always relying on plugins to resolve this issue for them, now in a case scenario where such plugin doesn't work as aspected due to compatibility issues then this case becomes rampant and contentious to resolve. How to fix duplicate content of this kind is to edit all affected pages, most SEO analysis tool can provide you the affected pages or you go through your search consoles on Google or webmaster tool on Bing.
This is another issue of plagiarism and it is quite common with scraper websites, this also calls to the attention of syndicating tools that help distribute content across the web. It is a black hat tactic to utilize the same content ranking on search engines and use the same content to try to fool the search engines into ranking your content as fresh content, whilst it's a spinoff from another website ranking. And yes, duplicated content can actually outranked an original in this case.
This is why Google and other search engines have acknowledged the use of DMCA as a way to penalize such infringement and use of content which is under the protection of intellectual property as well, hence such cases should be issues with the plagiariser backed with a lawyer's handwriting.
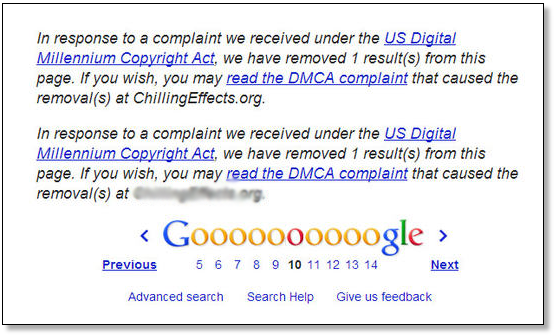
Recommended Read: How to Avoid Google DMCA Takedown Notice
Our Solution: To avoid a fracas on website duplicate content you should endeavor to include a link back to the original author, and likewise provide in the link a "rel=canonical" to tell Google that the URL is the original since search engines are yet to tell apart which content is the real author. One more step to go with this will be to try as much as possible not to use the full content of the website you are scraping if you are so keen on ranking for them, try to avoid this and edit them with your own words, you can use rewrite article spinners to some certain degree if they can emulate a readable and meaningful content.
While for syndication posts, you should work around making sure that the content on the original platform is marked as canonical while the other distribution feeds are a spinoff from the original, hence making the original content different in content from the distributed content but similar context.
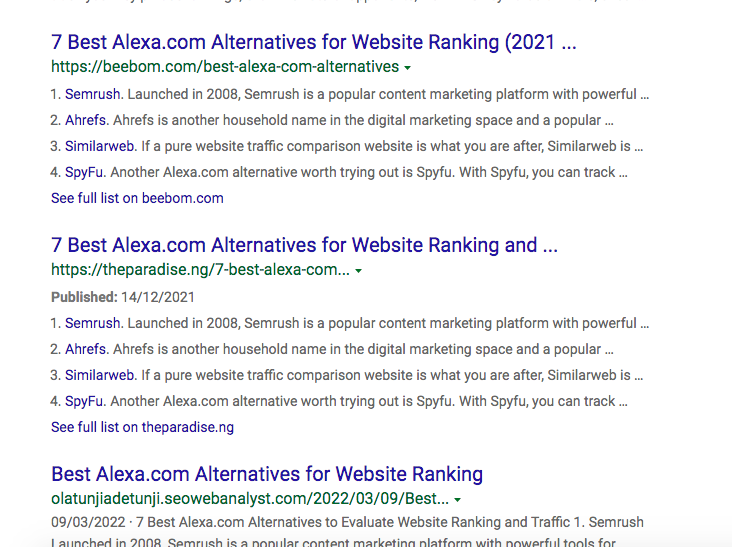
Observing from the image above you will be able to note that on Bing the top sites ranking on the search engine are actually ranking for the same keyword phrase and they all have the same content (I only edited my a bit but still ranked for top 5 for the keyword phrase "Best Alexa.com Alternatives for Website Ranking" and this brings me to the conclusion that duplicate content from scraped websites can also rank if the ranking content is on search engine).
There may be other bad factors that come into play here, but one thing is certain, that we were able to rank for this keyword basically for scraping the exact content and editing just 20% of it still got us on the first page. Now there might be penalties for this, but the idea here was the exact keyword match which gave use more headstrong leverage, besides this keyword other keywords the original content was ranking for we were not on the top 30 list.
According to Google, duplicate content won’t tank your SEO rankings. They specifically say:
“Duplicate content on a site is not grounds for action on that site unless it appears that the intent of the duplicate content is to be deceptive and manipulate search engine results. If your site suffers from duplicate content issues, and you don’t follow the advice listed in this document, we do a good job of choosing a version of the content to show in our search results.”
That does not mean we should take such action likely by spamming the web with duplicate contents (another bad culprit will be RSS Feed aggregator sites utilized by bloggers). I believe with the solutions provided above and the application of them in your content you can actually still rewrite and rank for an existing post and have more targeted focus keywords to rank for unlike what we ended up with when we scraped an original content (yes we provided the canonical link back to the original author), with this article you can now make a decision if duplicate content is bad for SEO.

I am a seo web analyst and have a love for anything online marketing. Have been able to perform researches using the built up internet marketing tool; seo web analyst as a case study and will be using the web marketing tool (platform).
How To Fix GA4 Showing Wrong Domain Traffic
How To Reactivate Google Adsense Account
How Do You Write Pitch Deck That Wins Investors
Effective Lead Magnet Funnel Examples For Businesses
How To Promote FMCG Products Using Digital Marketing
The Main Objectives Of SEO in Digital Marketing
How Artificial Intelligence Is Transforming Digital Marketing
Google CEO Sundar Pichai: Search will profoundly change in 2025
3 Most Important Business Growth Strategies
Top 20 Work From Home Job Skills




