How To Fix Index Coverage Issues Google Webmaster
Google indexing is a very technical aspect of a webmaster especially in SEO, in this article I will be explaining the issues I went through trying to resolve my Google index coverage warnings.
But first, let's discuss what is Google Indexing?
Google indexing in a lame term can be likened to a system caching and archiving a web page on the web. Then displaying these web pages to end-users that execute a search via pertinent keyword phrases that are related to the cached and archived pages.

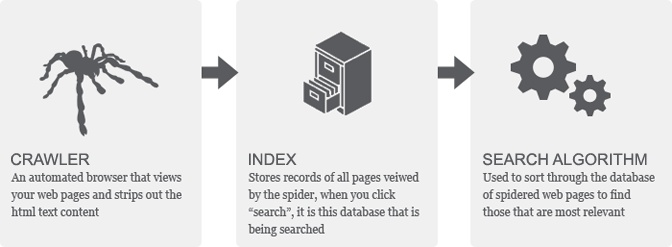
There are 3 steps the search engine uses in other to execute indexing of a website and they are;
Discovery
First, Google has to discover your web page URL, via the web, where it extracts other links to discover. These it classifies as pages, these pages are discovered either via your well-structured site map or internal and external links (inbound or outbound URL) that point to them individually.Crawling
Next, Google cache the page by going through every element of the website to have a carbon copy of it. Google uses its algorithms to understand the page priority couple with easy-to-use tags by webmasters that assist the search engine to know which pages are of importance to the website, you can define them on the webpage and your sitemap.Indexing
Finally, Google extracts the content of a page. Google evaluates quality and checks if the content is unique. Also, this is the step when Google renders pages to see all of their content, evaluate their layout, and various other elements. If everything is fine, the page gets indexed.
How Do You Know Google Indexed Your Website?
There is a simple method to deploy and one of them is to do a search site:yourdomain.com in Google.
This same method can be used for other search engines like Bing, Yahoo, Yandex, Baidu, etc
When you have done this you should be able to see the search results showing you how many pages of your website are currently being indexed by the search engine.
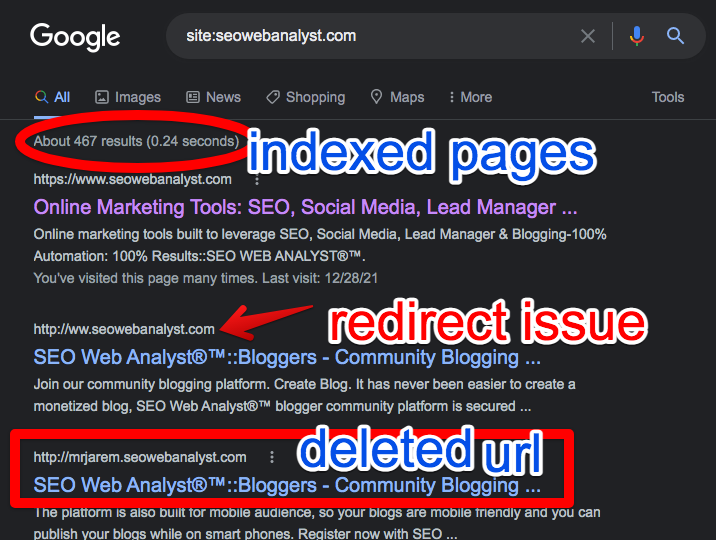
A search for our site index reveals the same exact pages being indexed on our Google Coverage page, but right there we could actually see some errors ourselves that denotes it's been a while Google has actually re-indexed our pages, as illustrated in the image above we have a redirect issue that was solved during our post on "Google Analytics Redundant Hostname", this will explain the need of having Google analytics as a webmaster.
Our next issue here was a deleted URL that is still relevant in search results, WHY? it seems Google is yet to re-evaluate our other links as we have resolved and deleted all the ghost links on our website.
To further understand if our webpages are actually being indexed by Google we did another individual search of a single page using site:subdomain.yourdomain.com on Google.
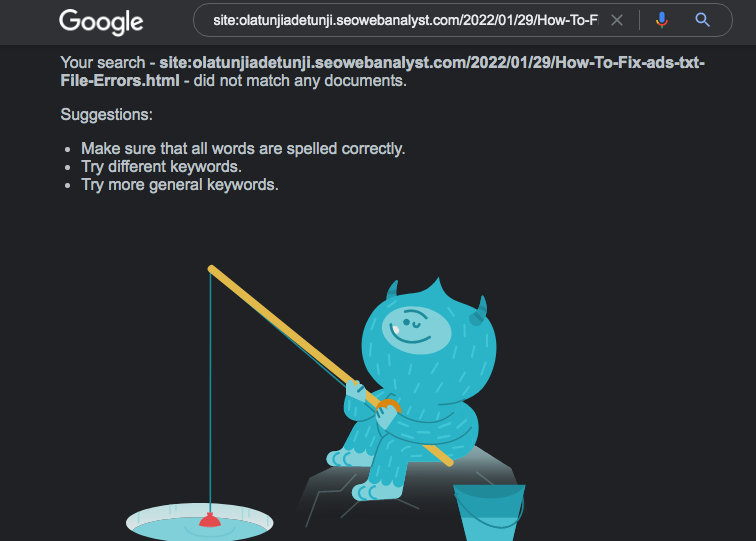
What this result denotes is that Google has not indexed any new pages from our server since January 2022 and we are in February, which does not sit well with me. I had to visit my Google Search Console dashboard at this point, and whole and behold what I discover was dreadful to me as I KNEW THE IMPLICATION OF THIS ERRORS (my organic traffic will suffer).
What is Google Coverage issue?
These are set of warnings related to webmasters on their Google Search Console Coverage index dashboard that highlights the four categories of how their web pages versus their submitted URLs perform during Google indexing.
It should be known that Google is facing serious indexing issues today, affecting numerous businesses around the world. Despite official announcements that the indexing issues have been fixed, the problems appear to persist.
Google is, without a doubt, one of the biggest and clearest monopolies in the world. Its closest search competitor, Bing, has only 2% of the market – hardly a significant threat to Google’s 90%. So, what happens when Google’s SERP isn’t working correctly?
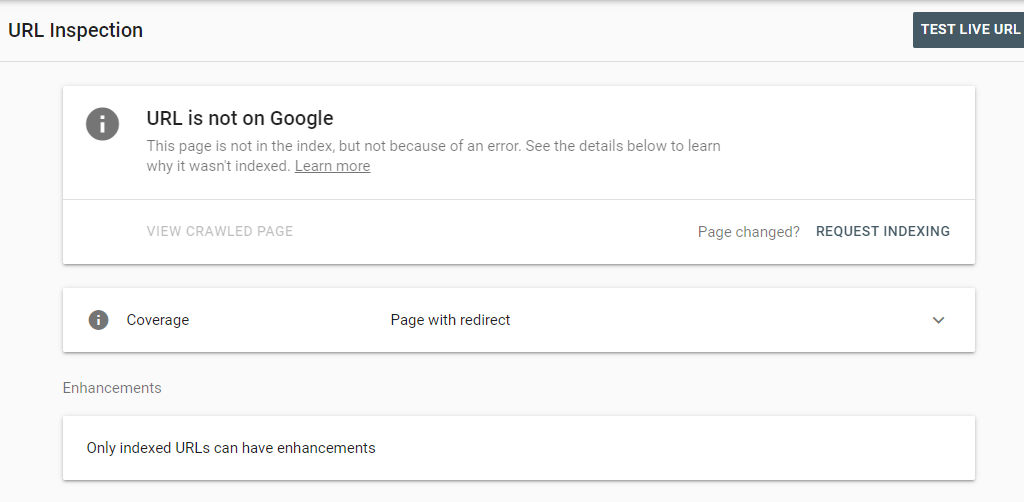
A good example of this case scenario will be when you have a website that is Ok for indexing and the search engine does not recognize it as being Ok, in the image above your page might not have any issue and yet Google will give off a false warning or may not index your page based on a rogue issue. Such cases are possible as explained in the quoted statement above. Your best bet will be to have the URL go through a TEST LIVE URL when you get a return message similar to the one above with all GREEN remarks, then you submit it for indexing.
From the image below you can see from our earlier test on the search engine that pages indexed by Google are quite the same as the search console dashboard, with the excluded pages outweighing the indexed pages in share quantity.
Excluded pages in the Google webmaster search console are indexed pages that will not appear on search engines, although Google states that the warnings enlisted are probably caused intentionally, I beg to differ, as they have excluded so many pages which to me smell fishy and it requires me to dig deeper and resolve them.
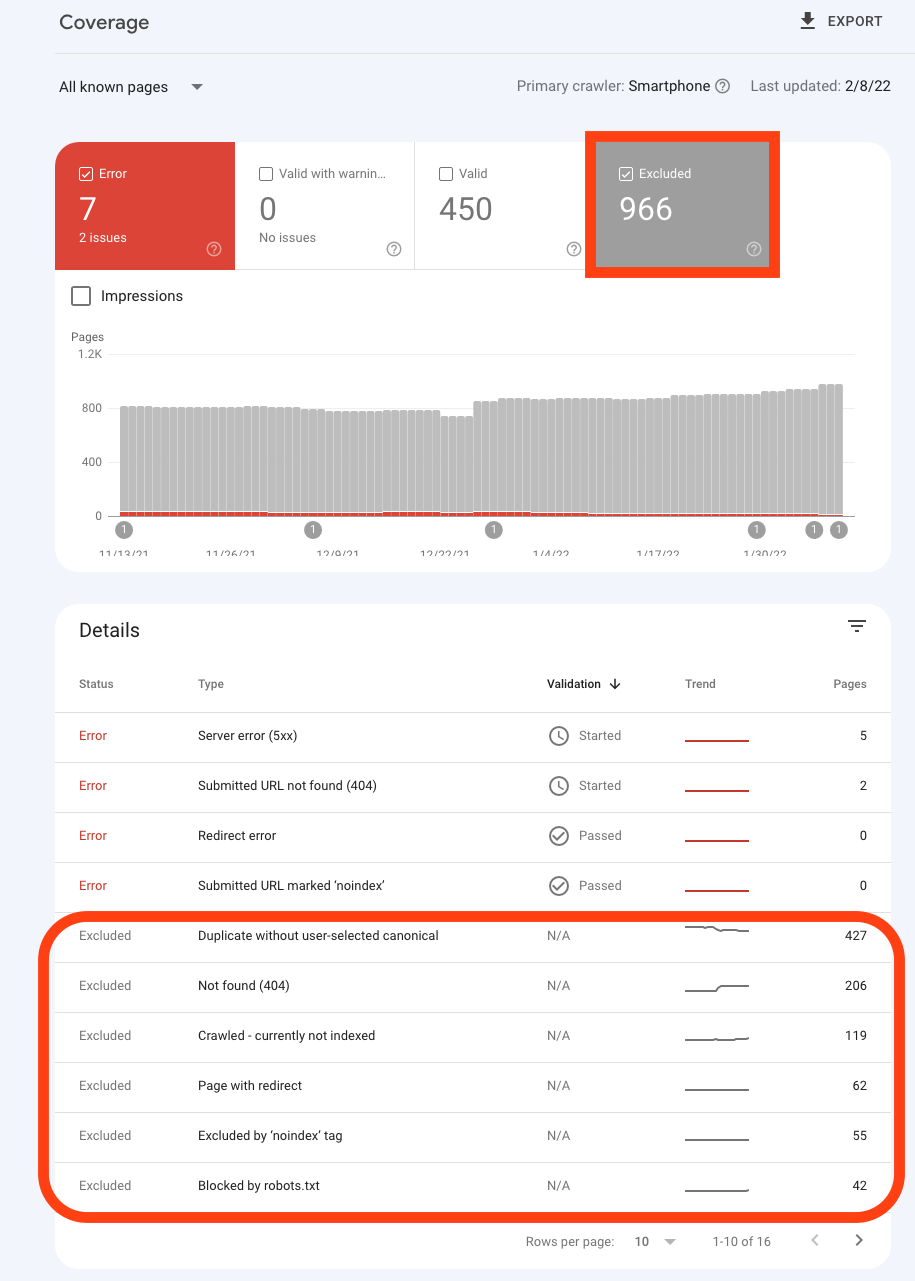
List of Google Coverage Index Issues
This list of errors is a warning that was received on my Google Coverage Indexed pages, yours may differ in language but my best bet is if you can use mine as a guideline to check and provide solutions even before it affects your web pages, you will be safe from any future coverage index issues. On your dashboard, you will notice you have four categories of reports about your web pages indexing and this includes;
Error pages: They are pages that Google couldn't index based on the warning issues stated, the implication is that you will not gain any organic traffic from them, the best option will be to resolve the coverage issues as stated, including how to fix them.
Valid with warnings pages: They are pages already indexed by Google, and already on searches, this may lead to errors that are not deliberate or you no longer want them on searches but have issues eg the deleted URL showing on Google (from our image above). The best option will be to resolve the coverage issues as stated, including how to fix them.
Valid pages: They are pages already indexed by Google and have no issues as they meet all the criteria for display on Google search, you are advised to do nothing at this point technically on these pages.
Excluded pages: They are pages that have not been indexed deliberately by Google, this might be the goal of the page or not, the best approach will be to resolve the coverage issues of the pages that were not supposed to be listed thereby fixing their respective warnings.
Based on the coverage warning issues on my dashboard I will address the respective solutions I applied individually, this might come in handy for your case scenarios as well.
Error pages
1.) HTTP Server Response Code
The HTTP Server Response Code is a piece of header information about your web page that is transmitted via your server, there are five different categories and their function is as described below;
- 1xx informational response – the request was received, continuing process
- 2xx successful – the request was successfully received, understood, and accepted
- 3xx redirection – further action needs to be taken in order to complete the request
- 4xx client error – the request contains bad syntax or cannot be fulfilled
- 5xx server error – the server failed to fulfill an apparently valid request
Knowing what each error stands for makes it very easy to resolve them, eg the 5xx server error may occur when Google tries to index your page during your server downtime.
There are other reasons like bad syntax errors when you try to load a page and you have it showing the server cannot handle the request, this is due to bad coding on your page.
Our Solution: For our case, all I had to do was to fix badly coded pages that were not functioning well due to deprecated codes and remove all references to our deleted URLs a good example will be the deleted URL that is still showing up on Google indexed searches, imagine people visiting that subdomain page and they will all be sent to a 4xx server error.
other culprits for this type of warning can also be caused by redirect errors;
- A redirect chain that was too long
- A redirect loop
- A redirect URL that eventually exceeded the max URL length
- A bad or empty URL in the redirect chain
Google recommends Lighthouse, to get more details about the redirect.
2.) Submitted URL 404 not Found :
This is an often error when you mistype a URL and submit for indexing or the URL you have submitted does not exist, could be a link in your internal web page or an external link pointing to you (this is why a broken link checker is very essential in technical SEO). If you run a WordPress website I will advise you to simply create the missing page and have it part. This is our best solution that is less tasking unlike trying to remove the excluded page and edit all other websites that link to it.
Our Solution: For our case, the pages sighted by Google as "not being found" (404) were a complete blop by the search engine bot, this takes me back to the reference quotation I stated above about what happens when Google’s SERP isn’t working correctly? The answer to this is to simply do nothing and resubmit the URL for priority indexing.
3.) Submitted Url Marked no Index
This is simply an error of laying two contradicting rules on your web page for the search bot to follow, eg using a canonical tag alongside a noindex tag seems to be the raise for an alarm in our case and also the submission of noindex pages in the sitemap do cause these warnings.
Our Solution: It is quite straightforward, simply remove the meta tag from the
Excluded pages
4.) Duplicate without User-selected canonical
This coverage issue seems to be the most popular index warning, moreover, I think Google now has a thing for the canonical tag, meaning in most cases you are required to add this tag into your HTML if not the current page will be assumed as the original page (that is what canonical means, don't index the current page you are on, but the one in the canonical URL).
Our Solution: view all affected pages and then specify the original canonical URLs we want Google to index or place the suggested one by Google on each page.
5.) Not Found (404)
Another common coverage issue is caused when the page returns a 404 error page when requested by Google who may discover the URL without any request or sitemap submission. They might be discovered via reciprocal link to the page, or possibly the page existed before and was deleted. Googlebot will probably continue to try this URL for some period of time; there is no way to tell Googlebot to permanently forget a URL, although it will crawl it less and less often. 404 responses are not a problem, if intentional.
Our Solution: We recommend a 301 redirect pointing to the new location of the URL (web page) but in our case, the subject pages were a mix of parameter URLs, deleted URLs, and non-existing URLs (How did Google find this URL was a sledgehammer to the head). Our best option was to check on our .htaccess file and utilize the Google Parmeter tool;
https://www.google.com/webmasters/tools/crawl-url-parameters?hl=en&siteUrl=https://www.yourverifiedwebsite.comYou can read more on using parameters here.
6.) Crawled currently not indexed
Not to be mistaken with Discovered currently not indexed; this error is as straightforward as its latter. To simply put, Google has done all it needs to do but is yet to index the page, which is the final stage of indexing.
Our Solution: I will suggest you go through the list of pages and rectify those you don't want indexing by removing them and then resubmitting your sitemap or manually submitting them for priority indexing via URL INSPECTION tool from your search console webmaster dashboard.
7.) Page with redirect
We have talked about this issue in the server error response and it is one of the culprits that can cause such errors as well, but in this case, it simply states those pages that have a redirect to another page instead of a 301 redirect (which seems to be Google's approved for of redirect).
Our Solution: Simply convert the pages to a 301 permanent redirect you can always take it off when you have sorted out the page so don't use window header or location header redirect for referring one page to the other. You can read on how to 301 redirect here
8.) Excluded by "noindex" tag
This is practically an intentional action by you or not, you have simply denied Google bot from indexing the page, meaning they discovered, crawled the page but were not permitted to index it.
Our Solution: Going through our list, we find them succinct to what we intend them to be, all unnecessary pages were found here, if you notice a page of yours that needs to be indexed simply go to your page editor and remove the "noindex" tag from that page and then resubmit the page via URL Inspection tool.
9.) Blocked by robot.txt
similar to Exclude by "noindex" tag only difference here is that you are blocking the indexing of the page via your robot.txt file. The suggested solution will be to view the pages and be sure they are what you want, if not go back to your robot.txt file and remove the disallow page or directory path you might have blocked. The image below gives a pictorial view of what you can do with your robot.txt file.
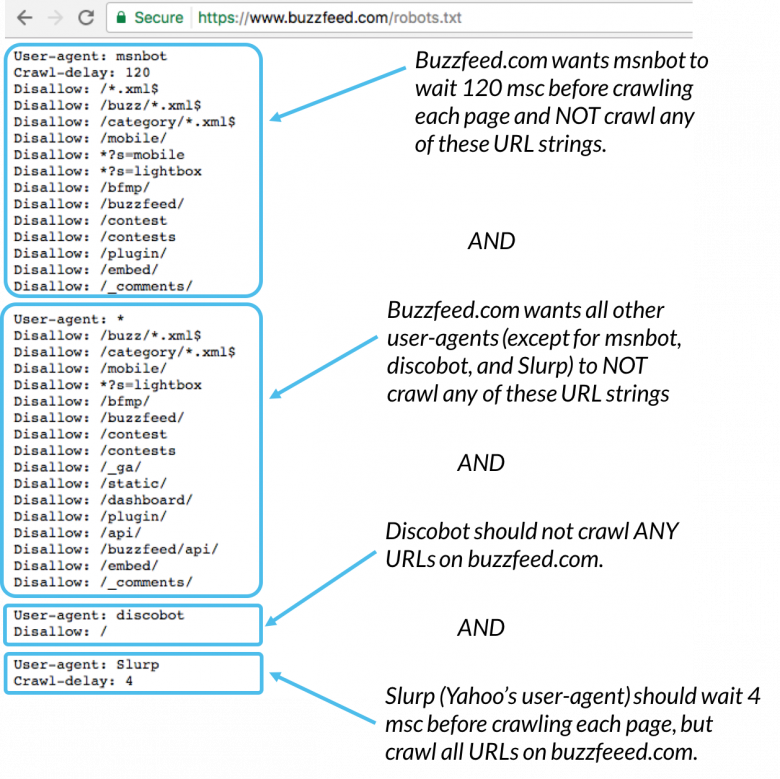
10.) Alternate page with proper canonical tag
Quoting Google alternate page with proper canonical tag is duplicates of a page that Google recognizes as canonical. This page correctly points to the canonical page, so there is nothing for you to do. My advice will be to go through them and verify the pages, in our case this issue was raised by another misuse of tags, the use of rel="alternate" hreflang="en-us" and rel=canonical pointing to the same URL
Our Solution: I will suggest not to use rel=alternate on the same page with rel=canonical pointing to the same page, you must point it to a different page having a different language declaration. In our case this issue was raised by another misuse of tags, the use of rel="alternate" hreflang="en-us" and rel=canonical pointing to a different URL having the same content, when using the rel=alternate make sure it is used to point to another language version of the same content eg hreflang="fr-fr" specify the URL page content is in French. Note: It has the same content as the page Google index but in a different language, thus won't be seen as duplicate because of this tag.
11.) Blocked due to access forbidden
The user agent provided credentials but was not granted access. However, Googlebot never provides credentials, so your server is returning this error incorrectly. This error should either be fixed, or the page should be blocked by robots.txt or noindex.
12.) Soft 404
Google does not take likely with pages having a soft 404 response code, this is a URL that returns a page telling the user that the page does not exist and also a 200 (success) status code. In some cases, it might be a page with little or no content (for example, a sparsely populated or empty page), mostly found in coded pages that need to request a syntax response.
Our Solution: you can either remove them or block them from being indexed you can also view some Google recommendations on resolving soft 404 here
13.) Duplicate, Google choose a different canonical than user
Similar issue with the Duplicate, submitted URL not selected as canonical. But differ in the sense that you did not request the indexing of the URL, but Google still did it and found them to be duplicated, to explain this further, the page is marked as canonical for a set of pages, but Google thinks another URL makes a better canonical. Google indexed the page that is considered canonical rather than the one you submitted.
Our Solution: Simply remove the duplicate content and point your canonical tag to the preferred Google URL
14.) Discovered currently not indexed
This is a simple issue and you have nothing to fear, it only means Google has discovered your URL but is yet to crawl and index it. You simply have to wait for this turn of events.
15.) Duplicate, Submitted Url not selected as canonical
This is quite a bizarre issue, it simply means you submitted a URL for indexing, which turns out to be a duplicate of another URL without you specifying a canonical URL on either, this, in turn, prompts google to choose a preferred canonical version to be an indexed version for you. The difference between this status and "Google chose different canonical than user" is that here you have explicitly requested indexing.
Our Solution: Simply add the rel=canonical tag to these pages pointing to their exact URL.
Conclusion
One thing I noticed from my investigation of the Google index coverage issue was that some of these issues were caused by my negligence while others were due to Google bot indexing inappropriately, and furthermore, most of the issues are due to not properly tagging or providing the technicality needed for the bot to execute its functions correctly.
A rule of thumb that will help facilitate a reduction in these issues will be to have a primary domain URL most preferable https://www version of your domain name, then 301 redirect all other versions to this primary domain, if you have the time you can include the rel=canonical meta tag to individual URLs of your webpage all having https://www. If you don't have a site wild SSL no biggie (if you run a subdomain), simply make sure that the http://www. is prioritize.
Do not use any version of the other variances as anchor links or nav links to other pages, eg http://www.yourdomain.com/blog does not redirect to https://www.yourdomain.com/blog is a red flag for indexing and on the same page, you did not provide a canonical URL. To set up a redirect for directory paths via .htaccess please you need to create the .htaccess file in the directory and use the code from
Redirect http to https using htaccess to get your desired result.
Another thing I observed was that contents that seem to be old and have no SEO value whatsoever are naturally added in the EXCLUDED PAGE by Google, my opinion is if they are evergreen posts then you have to rewrite the post and resubmit for indexing. If you run a dated URL, then add on the page a reference link to a newer version or content.
After applying all our solutions, my next call to action was to resubmit the URL for inspection, but before that, I used the TEST LIVE URL, after a valid pass, I then request a reindexing. Another way around it will be to delete the old submitted sitemap and resubmit it again, please note Google is lazy, it will probably show you old indexed issues, but in due time (a month to 3 months max) the issues should be rectified.
Recommended Read: You might find this useful Google de-indexed my website from its crawler





